Intro
I see a lot of debates online in regards to how a certain piece of code is performing based on it’s time complexity and it seems that people think that an algorithms time complexity is directly proportional with how their software is performing which is not always true.
This article’s scope is the importance of critical thinking when it comes to code performance.
What does time complexity actually tell us and what it doesn’t
First let’s clarify what time complexity does and what it’s useful for. I’ll make an assumption that most people reading this article saw at some point this chart in one form or the other.
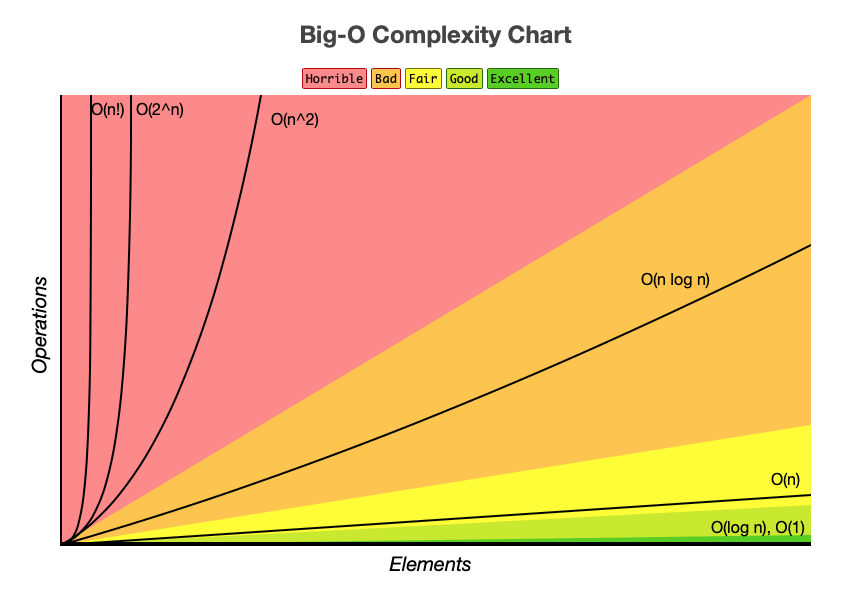
This chart has two axis, the horizontal axis gives you the n, which is considered the number of times a certain task the algorithm is performing and on the vertical axis the cost associated with a specific time complexity function.
This means that this graph shows you how does the complexity affect the performance as n scales. This is the important part. It shows you how the performance scales, not how the program is performing in the real world.
The function of the time complexity does not take into account constants. For example, if your algorithm passes an array one single time, 2 times, or 100 million times, the complexity will be $O(n)$. Furthermore, if for example $n$ is low enough and there’s a constant that’s 10 or 1000 times $n$, the time complexity will still be O(n).
The problem
w3resource: Frequency of Array Elements
The problem we are referencing is the “8. Frequency of Array Elements” which is simply having us count the number of times a number appears in an array.
So, smartass me starts solving the issue by creating a lookup table where the index would be the value and I can simply increment the count at that particular key giving me a time complexity of $O(n)$. Easy.
#include<stdio.h>
#define MAX_VAL 100
int main(){
int table[MAX_VAL];
for(int i=0; i<MAX_VAL; i++){
table[i] = 0;
}
int size;
printf("Enter the size of the array: ");
scanf("%d", &size);
int arr[size];
for(int i=0; i<size; i++){
printf("Enter the element with index %d: ", i);
scanf("%d", &arr[i]);
}
for(int i=0; i<size; i++){
table[arr[i]]++;
}
for(int i=0; i<MAX_VAL; i++){
if(table[i] != 0){
printf("Value: %d appears in the array %d times.\n", i, table[i]);
}
}
return 0;
}
Then I checked the problem’s proposed solution which had a time complexity of O(n^2). I’m not going to lie, this boosted my ego. Are you telling me I got a better performing algorithm than the person who created the problem?
The answer is yes and no at the same time because I cheated. I defined a maximum value that the array elements can have. I had to do this because there needs to be a one-to-one mapping between the lookup table indexes and the possible values the given array would have.
Real-world Cost Analysis
Let’s list some actual costs of both algorithms with different $n$ values and different max values. The real cost of my algorithm is the max value + n.
| Use case | My algorithm’s cost | Proposed algorithm’s cost |
|---|---|---|
| N=100 and MaxVal = 100 | 200 | 1,000 |
| N=100 and MaxVal = 1,000 | 1,100 | 1,000 |
| N=100 and MaxVal = 1,000,000 | 1,000,100 | 1,000 |
Damn… My algorithm sucks… Not really. My algorithm simply scales better the lower the max value is and the larger $n$ is.
| Use case | My algorithm’s cost | Proposed algorithm’s cost |
|---|---|---|
| N=1,000,000 and MaxVal = 100 | 1,000,100 | $10^12 |
| N=1,000,000 and MaxVal = 1,000 | 1,001,000 | $10^12 |
| N=1,000,000 and MaxVal = 1,000,000 | 2,000,000 | $10^12 |
Conclusion
Software engineering is more than following a set of rules and predetermined ways of doing things. It requires critical thinking and knowledge about the use case.
You know what? Screw the optimization. For most developers it’s way more than enough just to choose the right tool for the job.